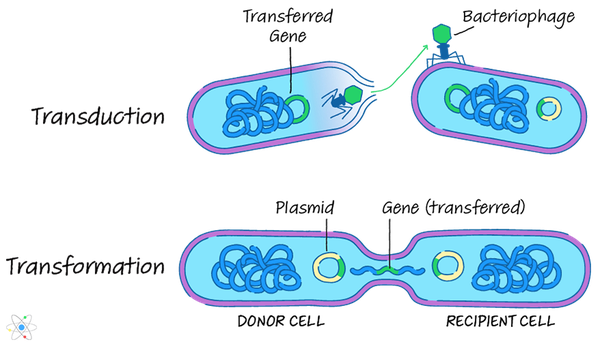
Centrální dogma molekulární biologie vysvětluje, že tok informací pro geny pochází z DNAgenetický kód do mezilehlá kopie RNA a pak do bílkoviny syntetizovány z kódu. Klíčové myšlenky, které jsou základem dogmatu, byly poprvé navrženy britským molekulárním biologem Francisem Crickem v roce 1958.
V roce 1970 se stalo všeobecně přijímaným, že RNA vytvořila kopie specifických genů z původní dvojité šroubovice DNA a poté vytvořila základ pro produkci proteinů z kopírovaného kódu.
Proces kopírování genů transkripcí genetického kódu a produkce proteinů translací kódu do řetězců aminokyselin se nazývá genová exprese. V závislosti na buňce a některých faktorech prostředí jsou určité geny exprimovány, zatímco jiné zůstávají spící. Genová exprese je řízena chemickými signály mezi buňkami a orgány živých organismů.
Objev alternativní sestřih a studium nekódujících částí DNA introny naznačují, že proces popsaný ústředním dogmatem biologie je složitější, než se původně předpokládalo. Jednoduché Sekvence DNA na RNA na protein má větve a variace, které pomáhají organismům přizpůsobit se měnícímu se prostředí
Informace kódované v proteinech nemohou ovlivnit původní kód DNA.
V jádře probíhá transkripce DNA
The Spirála DNA který kóduje genetickou informaci organismu, se nachází v jádru eukaryotických buněk. Prokaryotické buňky jsou buňky, které nemají jádro, takže Transkripce DNA, translace a syntéza bílkovin probíhají v cytoplazmě buňky podobným (ale jednodušším) způsobem proces přepisu / překladu.
v eukaryotické buňky, Molekuly DNA nemohou opustit jádro, takže buňky musí kopírovat genetický kód, aby syntetizovaly bílkoviny v buňce mimo jádro. Proces kopírování transkripce je iniciován nazývaným enzymem RNA polymeráza a má následující fáze:
- Zahájení. RNA polymeráza dočasně odděluje dva řetězce šroubovice DNA. Dva řetězce šroubovice DNA zůstávají připojené na obou stranách kopírované genové sekvence.
Kopírování. RNA polymeráza cestuje podél řetězců DNA a vytváří kopii genu na jednom z řetězců.
Sestřih. Vlákna DNA obsahují tzv. Sekvence kódující protein exonya jsou volány sekvence, které se nepoužívají při produkci bílkovin introny. Jelikož účelem transkripčního procesu je produkce RNA pro syntézu proteinů, intronová část genetického kódu je vyřazena pomocí sestřihového mechanismu.
Sekvence DNA zkopírovaná ve druhém stupni obsahuje exony a introny a je předchůdcem messengerové RNA.
Chcete-li odstranit introny, pre-mRNA vlákno je řezáno na rozhraní intron / exon. Intronová část vlákna tvoří kruhovou strukturu a opouští vlákno, což umožňuje spojit dva exony z obou stran intronu. Když je odstranění intronů dokončeno, je to nové vlákno mRNA zralá mRNA, a je připraven opustit jádro.
MRNA má kopii kódu pro protein
Proteiny jsou dlouhé řetězce aminokyseliny spojené peptidovými vazbami. Jsou zodpovědní za ovlivnění toho, jak buňka vypadá a co dělá. Tvoří buněčné struktury a hrají klíčovou roli v metabolismu. Působí jako enzymy a hormony a jsou uloženy v buněčných membránách, aby usnadnily přechod velkých molekul.
Sekvence řetězce aminokyselin pro protein je kódována v šroubovici DNA. Kód se skládá z následujících čtyř dusíkaté báze:
- Guanin (G)
- Cytosin (C)
- Adenin (A)
- Tymin (T)
Jedná se o dusíkaté báze a každý článek v řetězci DNA je tvořen párem bází. Guanin tvoří pár s cytosinem a adenin tvoří pár s thyminem. Odkazy dostávají jednopísmenná jména podle toho, která základna je u každého odkazu první. Páry bází se nazývají G, C, A a T pro vazby guanin-cytosin, cytosin-guanin, adenin-thymin a thymin-adenin.
Tři páry bází představují kód pro konkrétní aminokyselinu a nazývají se a kodon. Typický kodon může být nazýván GGA nebo ATC. Protože každé ze tří kodonových míst pro pár bází může mít čtyři různé konfigurace, je celkový počet kodonů 43 nebo 64.
Existuje asi 20 aminokyselin, které se používají při syntéze bílkovin, a existují také kodony pro signály spuštění a zastavení. Výsledkem je, že existuje dostatek kodonů k definování sekvence aminokyselin pro každý protein s určitými nadbytečnostmi.
MRNA je kopií kódu pro jeden protein.
Proteiny jsou produkovány ribozomy
Když mRNA opustí jádro, hledá a ribozom syntetizovat protein, pro který má kódované pokyny.
Ribozomy jsou továrny na buňku, které produkují buněčné proteiny. Jsou tvořeny malou částí, která čte mRNA, a větší částí, která sestavuje aminokyseliny ve správné sekvenci. Ribozom je tvořen ribozomální RNA a související proteiny.
Ribozomy se nacházejí buď plovoucí v buňce cytosol nebo připojené k buňce endoplazmatické retikulum (ER), řada membránou uzavřených vaků nalezených poblíž jádra. Když plovoucí ribozomy produkují proteiny, proteiny se uvolňují do buněčného cytosolu.
Pokud ribozomy připojené k ER produkují protein, je protein odeslán mimo buněčnou membránu a použit jinde. Buňky, které vylučují hormony a enzymy, mají obvykle k ER připojeno mnoho ribozomů a produkují proteiny pro vnější použití.
MRNA se váže na ribozom a může začít překlad kódu do odpovídajícího proteinu.
Překlad sestavuje specifický protein podle kódu mRNA
Plovoucí v buněčném cytosolu jsou nazývány aminokyseliny a malé molekuly RNA přenos RNA nebo tRNA. Pro každý typ aminokyseliny používané pro syntézu proteinů existuje molekula tRNA.
Když ribozom čte kód mRNA, vybere molekulu tRNA k přenosu odpovídající aminokyseliny do ribozomu. TRNA přináší molekulu specifikované aminokyseliny do ribozomu, který připojuje molekulu ve správné sekvenci k aminokyselinovému řetězci.
Pořadí událostí je následující:
- Zahájení. Jeden konec molekuly mRNA se váže na ribozom.
- Překlad. Ribozom čte první kodon mRNA kódu a vybírá odpovídající aminokyselinu z tRNA. Ribozom poté přečte druhý kodon a připojí druhou aminokyselinu k prvnímu.
- Dokončení. Ribozom si razí cestu mRNA řetězcem a současně produkuje odpovídající proteinový řetězec. Proteinový řetězec je sekvence aminokyselin s peptidové vazby formování a polypeptidový řetězec.
Některé proteiny se vyrábějí v dávkách, zatímco jiné se syntetizují nepřetržitě, aby vyhovovaly aktuálním potřebám buňky. Když ribozom produkuje protein, je informační tok centrálního dogmatu z DNA k proteinu dokončen.
Alternativní sestřih a účinky intronů
Nedávno byly studovány alternativy k přímému toku informací předpokládanému v centrálním dogmatu. v alternativní sestřih, pre-mRNA je rozřezána, aby se odstranily introny, ale sekvence exonů v kopírovaném řetězci DNA se změní.
To znamená, že z jedné sekvence kódu DNA mohou vzniknout dva různé proteiny. I když jsou introny vyřazovány jako nekódující genetické sekvence, mohou ovlivňovat kódování exonů a za určitých okolností mohou být zdrojem dalších genů.
Zatímco centrální dogma molekulární biologie zůstává platné, pokud jde o tok informací, podrobnosti o tom, jak přesně informace proudí z DNA k proteinům, jsou méně lineární než původně myslel.